
5 min. read
The purpose of an AI assistant is to provide users with the information they need, when they need it. This information can come from a variety of sources, including the web. In this article, we will discuss the two main approaches to indexing web content for an AI assistant: using a Vector Database or leveraging a Search Engine.
Vector Database
Databases have been around for a long time and are used to store structured data. Some well-known databases include MySQL, PostgreSQL, and MongoDB. We can store and retrieve data from these databases using SQL or NoSQL queries. For example, we can store structured user information in a table, such as name, email, and phone number. Later on, we can retrieve this information by querying the table and selecting the relevant columns. Due to the rise of AI and ML, many of these databases have started to support vector data types and operations.
Traditionally, these databases are not well-suited for storing and searching vectors, which are high-dimensional lists of numbers that represent data that has gone through a process called embedding. During the embedding process, the data is transformed into a vector that captures its semantic meaning. For example, a sentence can be transformed into a vector that represents its meaning. This allows us to compare the vectors of two sentences to determine how similar they are.
In the context of an AI assistant, we can use a Vector Database to store and index web content.
Here is a high-level view of how we would store data in a Vector Database:
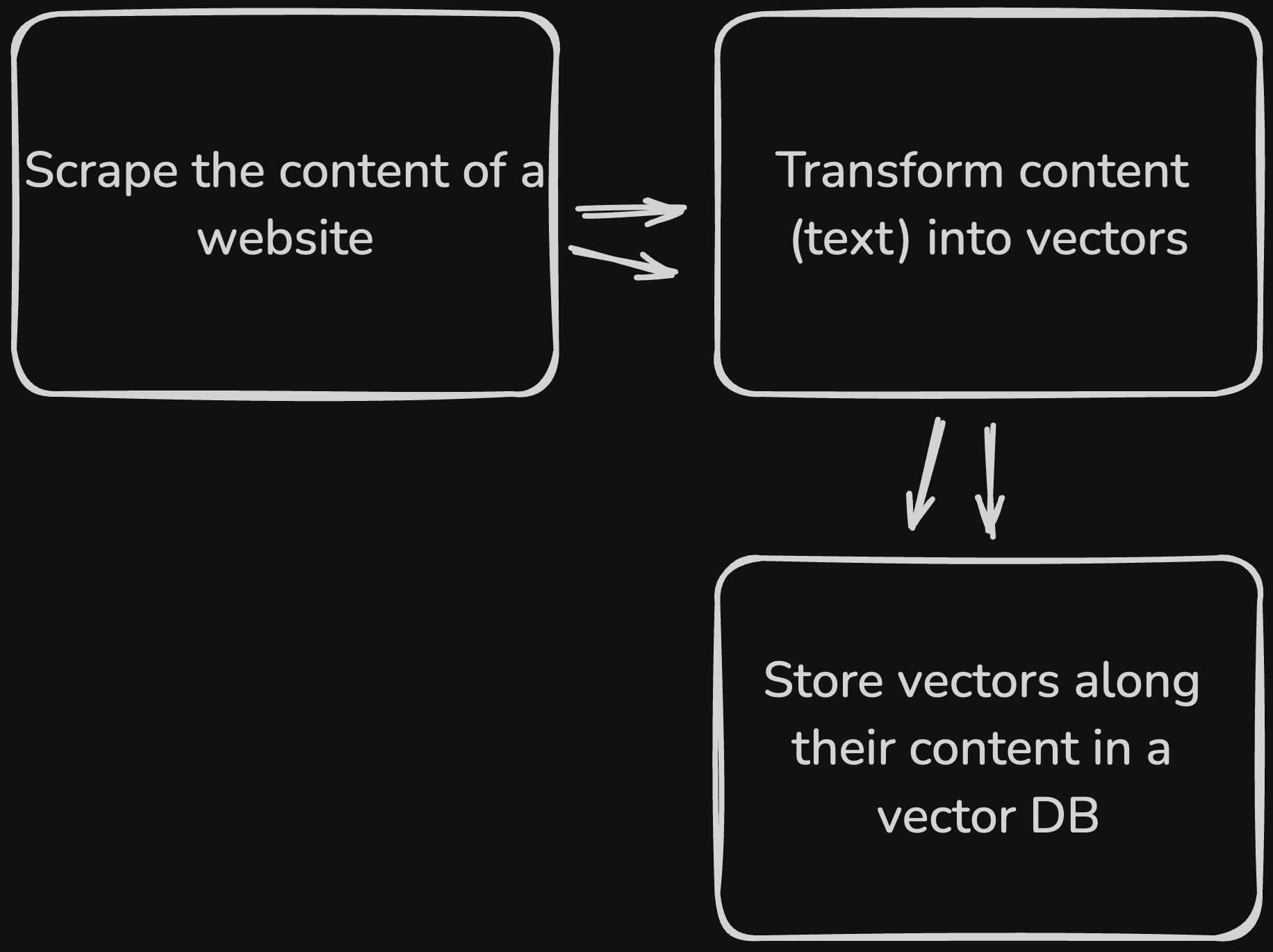
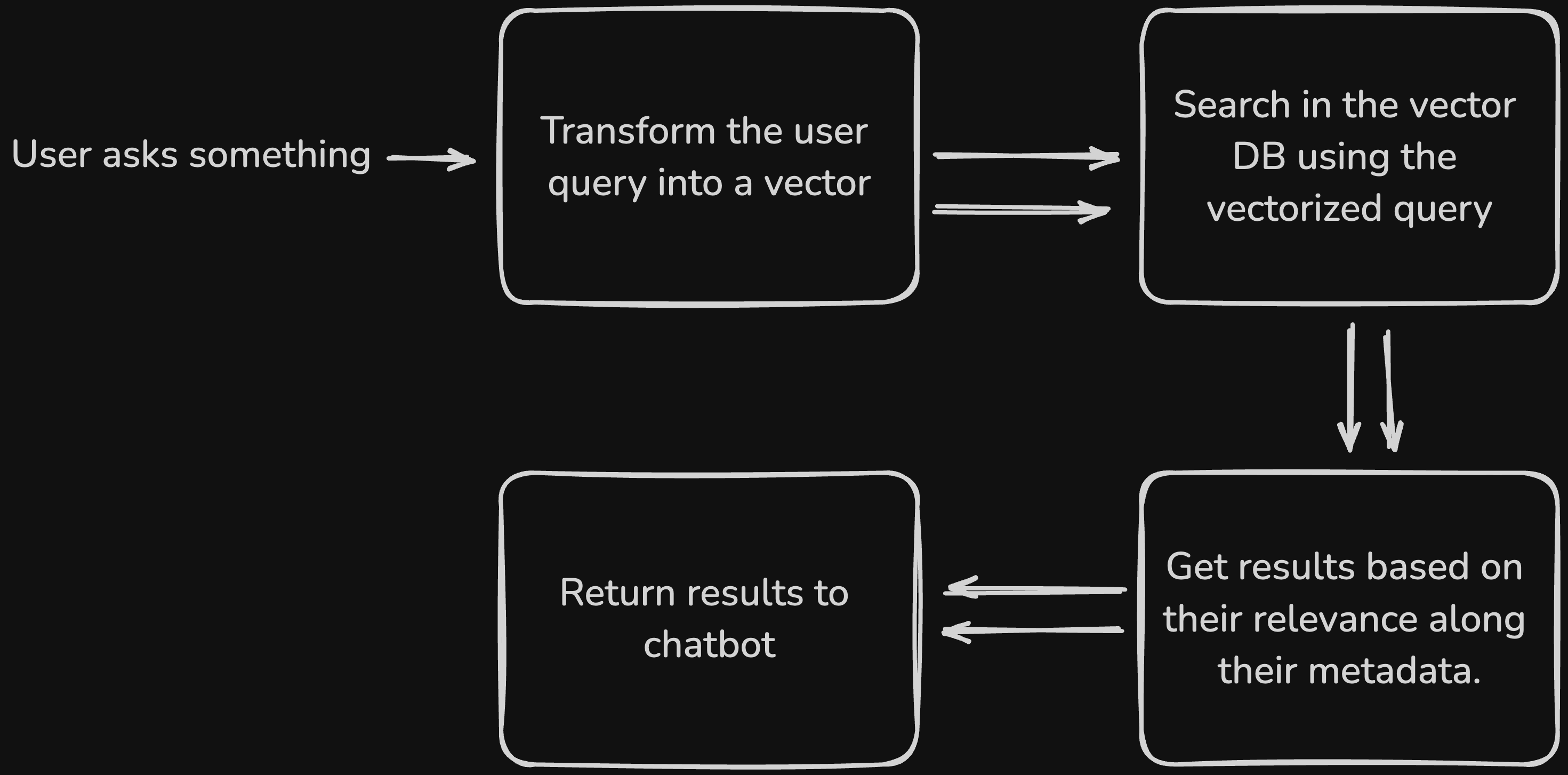
Now, when a user asks a question, we can embed the question into a vector and perform a search in the database for similar vectors. We can then retrieve the relevant content and present it to the user or chatbot for further processing.
Search Engine
Search engines are designed to index and search large amounts of unstructured data, such as web pages. They use algorithms to crawl the web, index the content, and provide relevant search results to users. Some well-known search engines include Google, Bing, and DuckDuckGo.
In the context of an AI assistant, we can leverage a search engine to index web content. When a user asks a question, we can use the search engine's API to perform a search and retrieve relevant content. We can then present this content to the user or chatbot for further processing.
Here is a high-level view of how we would use a search engine to answer a user's question:
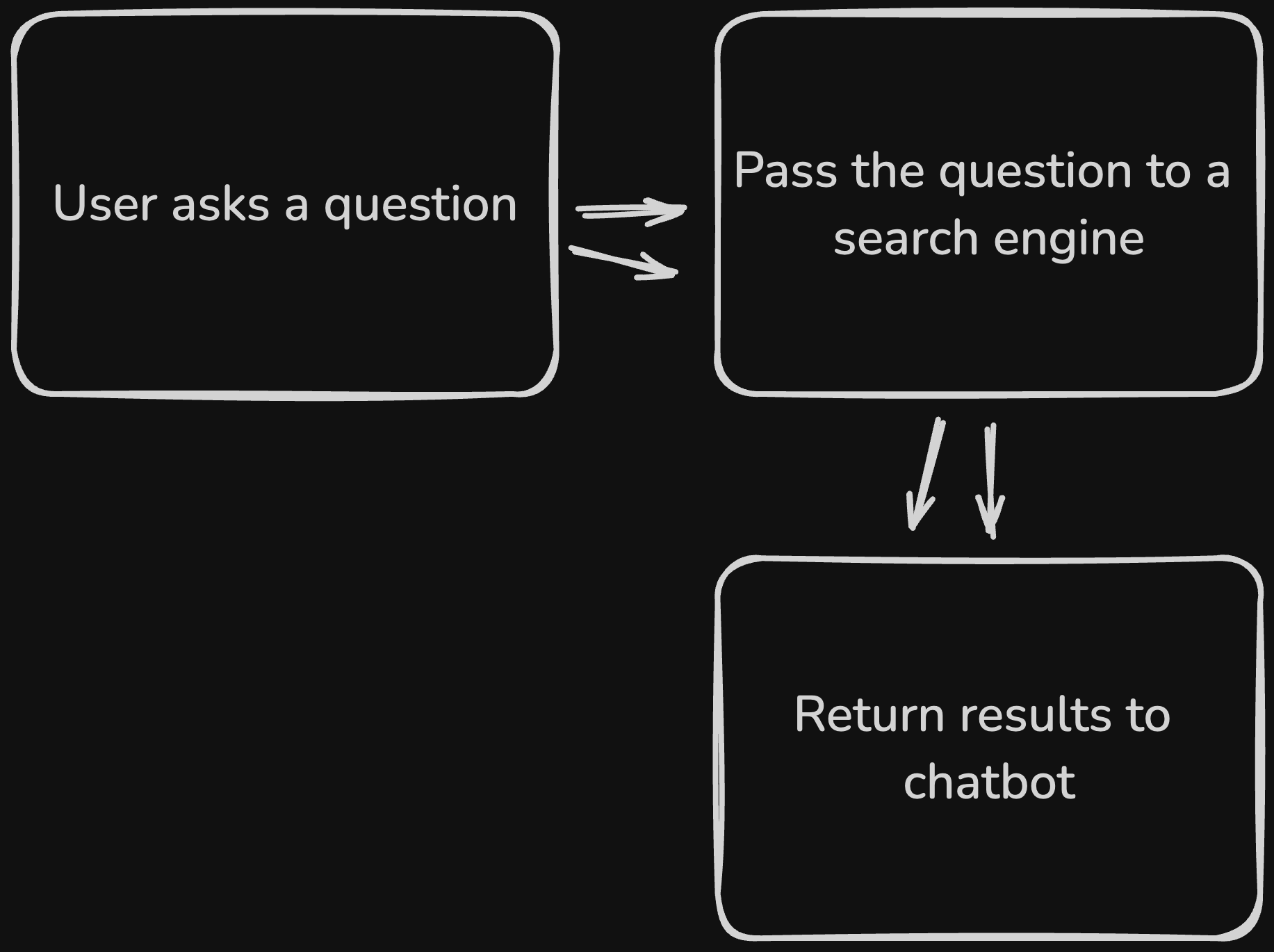
There is no need to index data when leveraging the search engine, as the search engine has already indexed the web content on its end. We simply need to perform a search and retrieve the relevant content. This is a more straightforward approach compared to using a Vector Database, as we do not need to worry about storing and indexing the data ourselves. However, we are limited by the capabilities of the search engine and the quality of the search results.
Which is Best?
You guessed it, it depends! Here are some factors to consider when deciding between using a Vector Database or leveraging a Search Engine:
-
Control over the Data: Using a Vector Database gives us more control over the data, as we can store and index it ourselves. This allows us to perform more advanced operations, such as vector similarity search. Leveraging a Search Engine does not give us as much control over the data, as the search engine has already indexed the content on its end.
-
Effort to Store and Index Data: Using a Vector Database requires more effort to store and index the data, as we need to transform the data into vectors and store it in the database. Leveraging a Search Engine is more straightforward and does not require us to store and index the data ourselves.
-
Up-to-date Content: This goes both ways. A Vector Database will have the most up-to-date content as long as we keep it updated. This means that you will need to build a system that regularly crawls the web and updates the database with new content. A Search Engine will have the most up-to-date content as long as the search engine itself is up-to-date. This means that you are relying on the search engine to keep their index up-to-date, which they are usually very good at, especially if the website is popular and has good SEO.
-
Speed and Performance: Using a Vector Database can be faster and more performant for certain operations, such as vector similarity search. Leveraging a Search Engine can be slower and less performant, as we are relying on the search engine's API to perform the search.
In conclusion, both approaches have their pros and cons, and the best approach depends on your specific use case and requirements. If you need more control over the data and want to perform advanced operations, a Vector Database may be the way to go. If you want a more straightforward approach and do not want to worry about storing and indexing the data yourself, leveraging a Search Engine may be the way to go.